

Say I wanted to make an app that recognizes avocado toast, and I have an AI model ready to go. All I need to do is feed it some pictures of avocado toast.
So the next time I’m out for brunch, I order avocado toast and take a picture:

One image in the bag! And if I label it “avocado toast” and send it to a human, they’ll know what avocado toast is and be able to recognize it. But machine learning algorithms need more than one picture in order to abstract the features that make this avocado toast and not some other kind of toast.
So next I go online and search for creative commons images of avocado toast:



That’s four down, ten thousand to go. Well, at least it’d be ten thousand if I wanted to have a highly accurate avocado toast recognizer using the industry standard of just throwing more and more data at it until it works.
But if I’m ok with having an AI that is only, say, 80% accurate, can I get the number of images down to a manageable level? If I’m taking the pictures myself, can I need even fewer images if I’m smart about how I take them? Maybe instead of spending time collecting thousands of pictures of avocado toast, some of that time would be better spent strategizing.
How much avocado toast does an AI really need?
1. More Avocado Toast with Avocado Toast Photoshoots
Maybe I notice all the above images are at a similar angle from above, and with one complete slice of toast just barely within the frame. They are all beautiful artistic photos. But I don’t want my toast recognizer to depend on the number of slices or how they are framed, and I don’t want it to fail in real world situations with unattractive toasts:

Avocado toast is avocado toast no matter the angle, no matter how many, and no matter whether you’d proudly share a picture of it. So as long as I’m taking photos, why not take a few, and let them be ugly?
In fact, I can take pictures all throughout the process, changing angles and lighting and background, to turn one snack into a photoshoot that collects 20 images for my dataset:

These 20 images might not be worth as much as 20 independent toast images would, but it’s so much easier than collecting even just two entirely unconnected toast images.
So how much more are these 20 images worth than 1? Was it worth my time to re-plate the toast onto different backgrounds? To nudge the slices around? Should I have taken even more variations, or did I reach the point of diminishing returns after the first few? Is this a good strategy at all?
I can make some guesses based on existing research, but there’s nothing like trying it yourself. So I decided to keep on gathering multi-image datasets on a single toast-making process. Here’s one for Blue Cheese Apple Honey Toast to add to my Not Avocado Toast dataset:
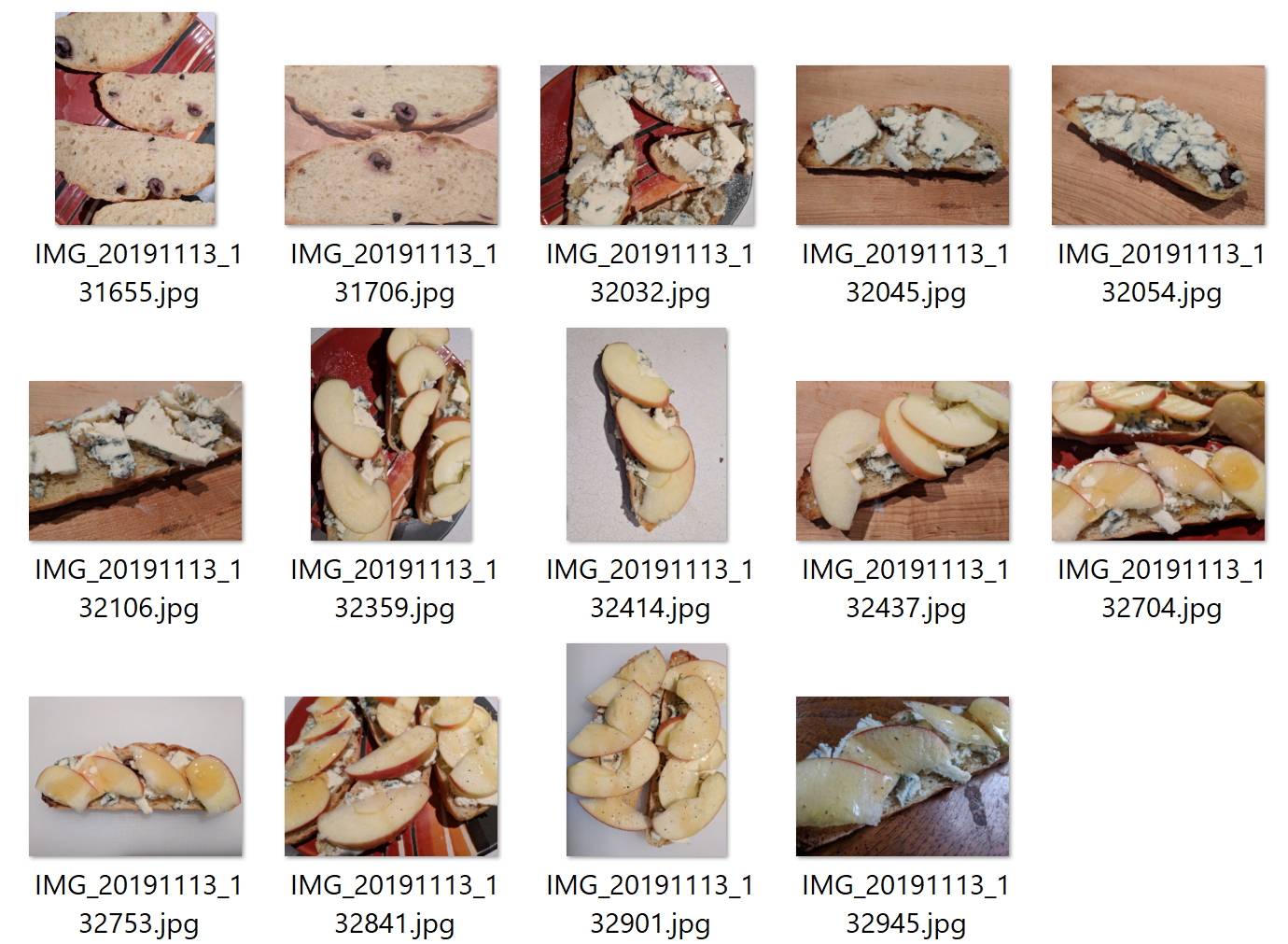
This time I took slightly fewer pictures. I figured I didn’t need so many variations on plain toast, since every toast I make will start with plain toast. I’m not sure how much I should worry about over-representing plain toast in my Not Avocado Toast dataset,1 but I’ll stick with my intuition for now.
2. Data Augmentation and Friends
There’s a well known technique in machine learning to turn one image into many images for your dataset, called data augmentation, where you make copies of an image and modify it with various filters. In the case of toast we should be able to flip or rotate the image, crop it a little, blur it a little, or shift the color slightly:




In fact, our toast recognizer AI already has this built into its training. It’s an easy way to turn my dataset of 100 pictures into 1000, which would be a respectable number if 90% of it weren’t almost the same as the first 10%. And of course there’s the fact that most of that 10% is repetitive too, being different pictures of the same toasts or toast-in-progress.
For automatic data augmentation you have to be careful not to do anything to the images that might make them unrecognizable, like shifting the hue too much or cropping out the important part:


In cases where more data is hard to come by but very valuable, sometimes it’s worth it to have people make variations by hand.2 This allows a greater range of image variations without accidentally creating bad data. For my AI that is specialized for toast and toast only, I expect it to work on the following hand-made edits:




For other applications I may want only whole-toast images, or only expect a certain range of sharpness or blurriness, or expect certain lighting. For toast, you can reverse the image to get another variation, but I wouldn’t include that in my augmentations if I wanted my AI to recognize letters of the alphabet.
The great thing about data augmentation is that there’s a bunch of research on it.3
We know data augmentation is useful, though artificially augmented images aren’t anywhere near as good as real new independent images. We should expect the similar images from our photoshoots to fall somewhere between the two in effectiveness. I’d also be curious whether it’s worth it to bother doing artificial data augmentation when you already have natural variations from a photoshoot. For a dataset this small you might as well, but for large datasets it might not be worth the extra computation.
3. Avocado Toast Alignment Space
Maybe with the right strategy I could improve my AI with a small set of carefully chosen Avocado Toasts that together represent all of their brethren. I like to imagine giving an AI a full sense of the world of possible avocado toasts just by feeding it the avocado toast archetypes. I won’t try my hand at creating the toast version of the Jungian Archetypes, but I will absolutely 100% create a Dungeons and Dragons-style alignment chart:

The Dungeons and Dragons alignment chart, which categorizes characters along the two dimensions of good/evil and lawful/chaotic, is not entirely dissimilar to how our AI works.4 During training, our AI tries to pick up on what features are important to categorizing toast. In its first layer, it only asks “how much green is in pixel #345? How much red is in pixel #9882?” etc etc. But we can hope that in later layers, as it looks at pixels in groups, it will start judging pictures with questions like “how much smooth green curve is in this picture?” and “do parts of it have a mushy green/yellow texture?”
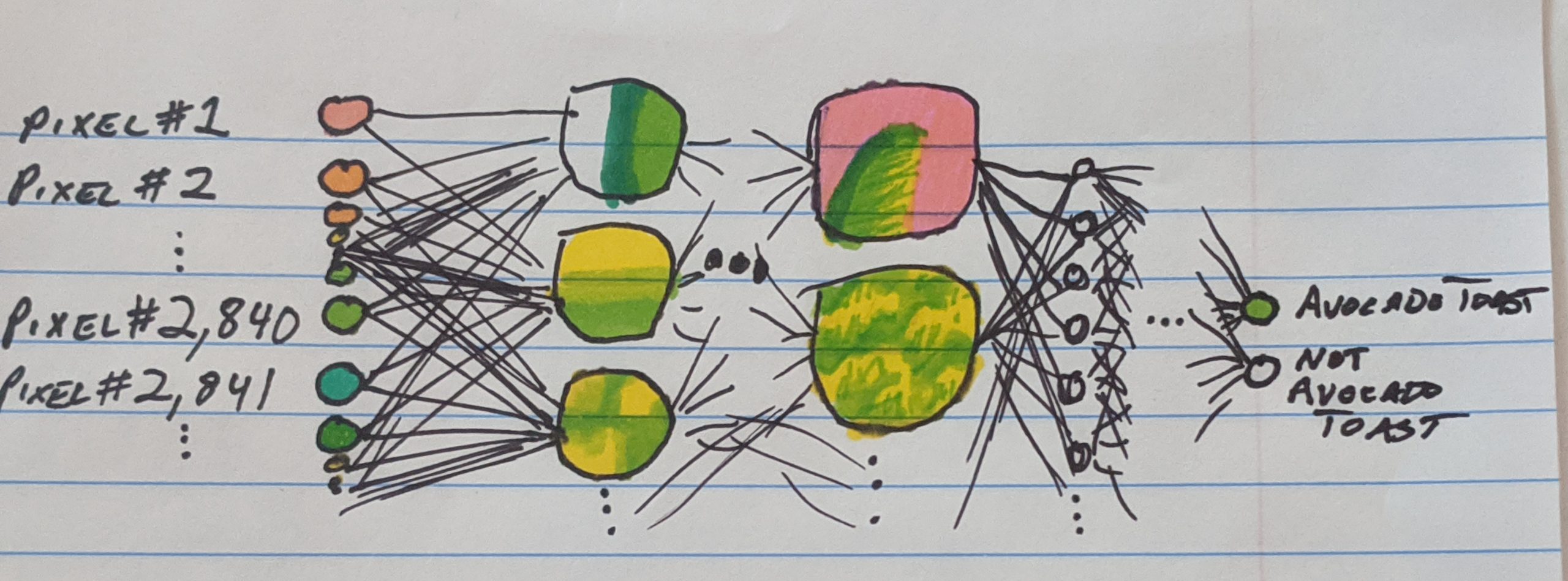
Most likely, especially as our AI is way overpowered for our tiny dataset, it is not asking very reasonable and obvious questions about how much green is on the toast but is instead doing something more akin to conspiracy theory logic. “Yes I know that when you look at the toast, you see that it is covered in green mush,” the AI might say, “but actually it has 6 brown pixels in a pattern that looks kind of like the letter h if you squint in this precise computational manner. And look here, on this cinnamon toast! It has a very similar pattern of 6 brown pixels! And so does this peanut butter toast! Now, check me if I’m wrong, but I’m pretty sure that cinnamon toast and peanut butter toast ARE NOT AVOCADO TOAST. So I’m 100% sure this isn’t avocado toast either, and your feelings about seeing green mush don’t change the facts. I am very good at logic and math. You can count the pixels yourself if you don’t believe me, go ahead, I’ll wait.”
With enough data, we can hope the random coincidences like those 6 brown pixels will become overwhelmed by better choices in features. The common wisdom in the field is that we should trust the AI to figure out what the best features are rather than directly telling it to look for the green stuff. Even if it initially goes astray it will set itself right once it gets a broader range of toast experience. But when you’re working with a small dataset it sure would be nice to poke it in the right direction! Especially as photos with similarities, whether through automatic data augmentation or a photoshoot of different angles and variations, are more likely to have irrelevant features in common that the AI will pick up on and think are important.
I’d love to be able to annotate by hand what I think some of the important features are, and then let the AI relax into an optimized version of that.

In the above picture, I annotated Crust as “irrelevant” because the presence of crust doesn’t help tell you whether it’s Avocado Toast or Not Avocado Toast. But the AI might use crust recognition to help in other ways, such as identifying what parts are the toast and what are background. Crust can also indicate the scale of the toast within the image, which might help with identifying avocado slices and mashed avocado texture at the correct scale, as some pictures will be taken from closer or further away.

I know with my human brain that what makes Avocado Toast Avocado Toast is the avocado, which comes either in slices or mush, and it is fairly recognizable it because it is green. But Not Avocado Toast can also have green, usually due to leafy greens such as arugula, so we have to look at the features that differentiate a leaf from either mushed or sliced avocado. To make a direct comparison to the Dungeons and Dragons alignment chart, let’s replace Order vs Chaos with Hard Edges vs Mushy, and Good vs Evil with Dark Green vs Yellow Green:

For some kinds of AI, the goal is to find a really effective alignment chart that you can put all the images into, and then calculate what line to cut along to separate the categories.

While 9 archetypical images and just two dimensions of alignment might be unrealistic, I do think data is worth more than people think it is. The current expectation is that AI companies can’t function without huge amounts of data, and therefore the companies must be huge and must collect all the data from their users if their services are to work at all. This exchange of data for free services is viewed by most users as fair or necessary, and only the huge companies have the compute power to work with that much data. Things might be different if AI companies had an incentive to pursue smaller AI and curated datasets.
4. Is It Avocado Toast?
I know my bespoke avocado toast recognizer will never compete with corporate-created models trained on a million images. In fact, since the only data it has seen is of toast, it doesn’t know the difference between toast and literally anything else. It assumes everything is toast, just either avocado toast or a different kind.
But now that the AI is fed and trained, we can look through its eyes to see how it categorizes non-toast objects, according to the standards of toast.





Sorry, I don’t make the rules.
These are all the actual results of the AI I created.
(More on this in Appendix 5.)
To take a brief philosophical detour, sometimes I wonder if all of us are kind of like the AI that only knows how to see things as avocado toast or not. Humans are prone to judging things with high confidence based on the standards they’ve learned for the things within their experience, while completely not seeing the truth of what something actually is because it’s outside their experience.
5. I Fed Avocado Toast to an AI and Here’s What Happened
I fed avocado toast to an AI and you’ve seen what happened… to the AI. But what happened to me?
I knew that if I wanted to keep improving my AI, I’d need images that were more independent from each other than the ones I’d been taking. I’d been basically making the same kind of avocado toast over and over, as seen in these six different days in September 2019:
 Delicious amazing heirloom tomatoes were in season, and I always use sliced avocado, rather than mashed avocado. What’s the point of mashing, unless you’re going to add other ingredients?
Delicious amazing heirloom tomatoes were in season, and I always use sliced avocado, rather than mashed avocado. What’s the point of mashing, unless you’re going to add other ingredients?
If I’m going to bother to mash, I’m going to step up my game. I might as well try to make the full range of possible avocado toasts. That’s when I thought of toast archetypes, and asked myself: “What would chaotic good avocado toast look like?”

In general the dataset I was building gave me that extra push I needed to get off my butt and make a food rather than eating something packaged or working through meals. And it encouraged me to expand my avocado toast palate to include a variety of different vegetables and proteins.

Workers in our field are notorious for getting overly focused with intense long hours that lead to unhealthy eating habits,5 and it’s not uncommon for folks to think of the body’s need for food as a nuisance and a liability rather than something to enjoy or spend time on. I feel a lot better when I eat something fresh and delicious. I know I should and that it’s worth the time, but it sure is easy to slip into bad habits.
Having these toast photoshoots be technically work made it easier to justify the time and interruption to eat a good food whenever I want one instead of growing slowly and subtly hangrier while pushing through work hours. And now that I’m in the habit of picking up the ingredients every week and making the recipes, it is much easier to do these things automatically without it feeling like an extra cognitive load.

So if you’ve got a snack or recipe you think you’d benefit from spending more time with, consider making an AI that needs to eat it. In this field we tend to treat our AI better than we treat ourselves, and apparently SOME of us are willing to cook to feed an AI when we wouldn’t cook just for ourselves. I could probably extend this lesson to other areas of my life.
Basically, while feeding avocado toast to an AI provided a lovely source of short-term amusement, this process will have long-term effects on me. Look at this toast now in my food repertoire:

I am forever changed.
This project also positively affected my social life, as I shared my toasts with colleagues who knew about the project and even received from them dozens more toasts to add to my dataset. For much of my friends and family my work can sound a bit abstract and difficult to connect to, but here was something where they could share tips and recipes, and enjoy the results. Using AI to strengthen human social bonds seems preferable to using AI to replace them.
Finally, this project also fulfilled its intended purpose of inspiring directions for research I wouldn’t have thought of without hands-on experience making and using a dataset. I mean, this AI may not be impressive, or useful, or… good. But I love it, and it is mine, it helped me explore a bunch of ideas that I think will come in handy later.
THE END, Kinda
Thus ends the general audience part of the post, thank you for reading!
For a slightly more technical or AI-invested audience, you are most welcome to read on.
Appendix 1: The “Coupon Collector Problem” as applied to the Value of Data
It is generally known that adding more data increases the effectiveness of your model in a logarithmic way,6 with the initial images adding a ton of value and then diminishing returns as your model approaches 100% accuracy.

How much of this depends on the assumption that you’re adding random new data, where each new piece of data is increasingly likely to have a lot in common with ones that came before? Maybe that’s kind of like how I kept adding avocado toasts to my dataset, but after 70 avocado toast pictures had still only filled out 5 parts of my alignment chart. It wasn’t until I stopped and thought about it that I realized my dataset was completely missing chaotic good toast and evil avocado toast, and instead of continuing on randomly for another 70 toasts (or more) I only needed to make 4 more toasts to complete the set.
Maybe with the right AI architecture, data would be worth more because it would describe these lower dimensional feature spaces more quickly, rather than needing to train over a ton of data just to get rid of the noise. Or maybe if we were more careful about how we collected data, rather than adding random data and hoping we get what we need.
It’s like the Coupon Collector Problem, a classic in probability. It’s named after collecting a complete set of coupons from cereal boxes, and also applies to collecting a complete set of trading cards from random packs, or a complete set of blind-bag toys. This problem and many variations have been well studied, and guess what kind of curve you get as you collect more samples in search of a complete set:
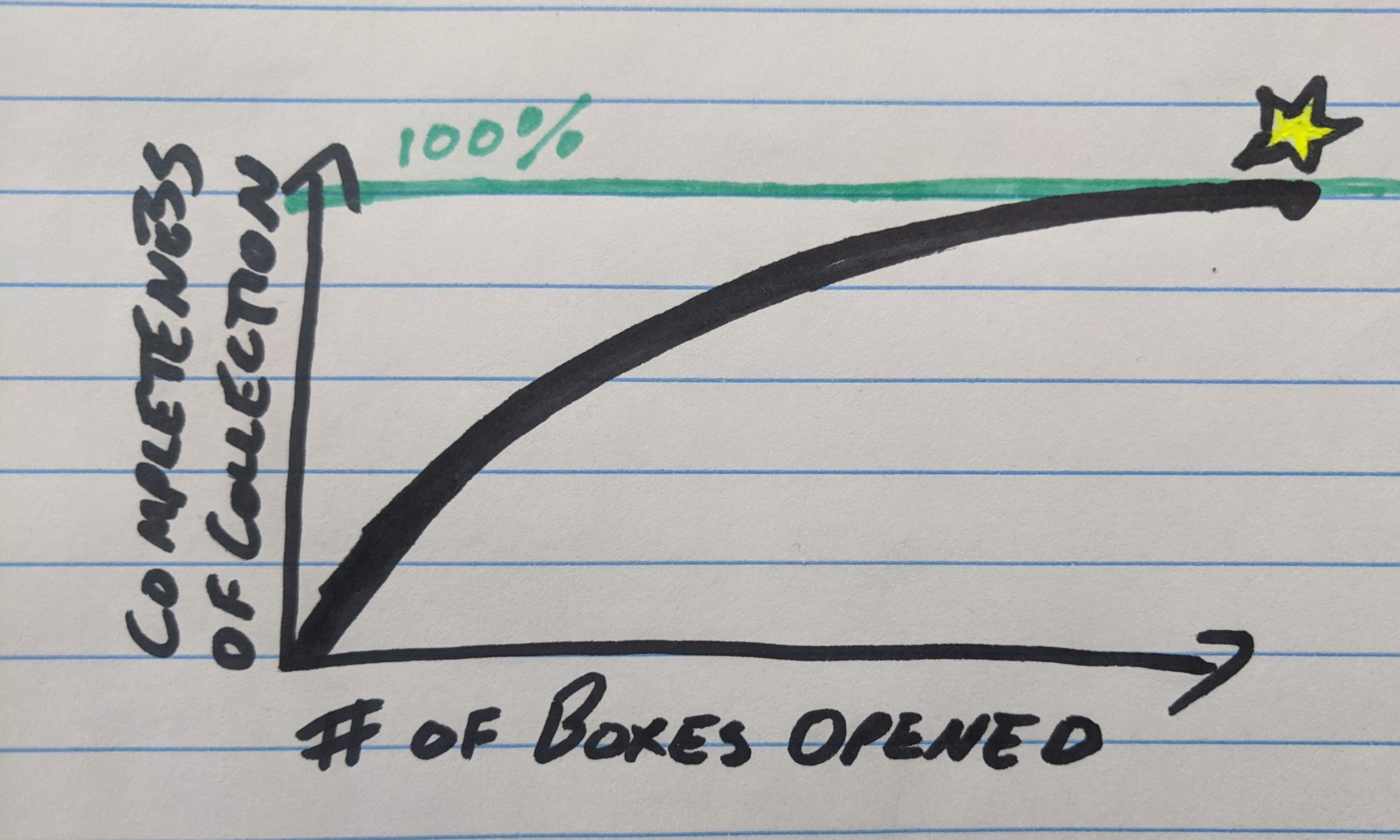
That the Coupon Collector Problem and AI data problem both involve collecting samples in search of completeness, and that both result in logarithmic behavior, may be a purely metaphorical connection. One key difference is that, at least in the original formulation, the number of collectible items is finite and thus we do expect to reach 100%, while there’s basically infinite possible toasts and if we managed to catalogue them all you can bet that by then someone will have invented a new kind of toast.
I’ll leave this here as a suggestion for research, as it sure would be nice if we could do for AI the equivalent of seeing through the boxes to collect what we need rather than buying an exponentially increasing number of mystery items. We would also get much more interesting market behavior for data if we could tell the rare items from the common ones, rather than our data budget being overwhelmed by the cost of buying piles of near-duplicates in a completely nontransparent way.
For example, the Black Lotus card in Magic The Gathering is famously expensive both because it is a rare collectible and because it is a powerful card with value in high-stakes tournaments.7 What if there’s an equivalent toast image that would make any toast AI more competitive?
Imagine a collectible card game with infinite unique cards, but many are similar to each other or complement each other in particular ways, and you need to collect and build a 10000-card deck to compete in tournaments with million-dollar prizes. But you can’t buy the ones you need because there’s no market for selling cards, no one has developed a deck-building strategy, and no one has bothered to figure out how to price individual cards. And no one bothers to fix those things because why buy cards when most people will just give you their spare cards for free because they don’t have enough for a full deck anyway. A Black Lotus becomes worth just as much as anything else, because the market doesn’t have the mechanisms it needs to know better.

Appendix 2: A Cautionary Tale
When I started training my model on photoshoots of many related images, I expected the accuracy to go up as compared to my previous model that used a smaller set of unique individual toasts. The problem was that the model soon started showing over 99% accuracy. This had to be wrong. The dataset was too small, and with some testing I found that my Avocado Toast AI performed exactly as poorly as I expected it to in real world situations. Meanwhile, tried-and-true standard methods of testing accuracy were telling me I could put the “99% accurate” stamp of approval on my product.
My model used the standard method of a train/test split, where the images are randomly sorted into two groups. One group gets used to train the AI, and then after it’s trained you test it on the images it has never seen before. It wouldn’t be fair to test an AI on the same data it was trained on, because the model could basically “memorize” what the correct answers are for those specific images.
My guess for what went wrong is that, by feeding my AI related images, it became very likely that some very similar pictures of the same exact toast would end up being trained on and then tested. This lets the AI fake its way through categorizing the images in the test image set, creating a higher score than it would get with truly independent toast images. The architecture knew not to include its own automatic data augmentation images in the test set, but it didn’t know there were near-duplicates in the original dataset.
This made me wonder how often this happens with commercial AI models, where large datasets and powerful models would make a high score look like a good thing rather than a red flag. If there’s duplicates in the dataset, or if some of the images are correlated, it might trick engineers into thinking their model is performing better than it actually will when put in a real world situation. This seems especially likely when data is collected through web scraping or crowdsourcing, and it becomes more likely the more data you collect.
This is part of why de-duplification is a standard part of data cleanup, but usually that is more about removing exact duplicates or near-indistinguishable duplicates. De-duplification might not catch similar images like the ones in my toast photoshoots, and there’s a certain art to how similar counts as the same depending on the application.
As I added more photoshoot sets, and expanded the variety of toasts I was making, the accuracy went down again. It can always be a bit disheartening to see that adding more data makes your model apparently perform worse, but I knew that in reality the model was becoming better. Focusing too much on the numbers disincentivizes adding new varieties of toast that widen the scope of what the model sees during training and testing, but sometimes you have to use your own good judgement rather than going by what the numbers say. The only test that matters is the real world.
Appendix 3: Train/Test splits, correlated data, and lumpy datasets
For my toast dataset, when I create the train/test split I don’t want to split images from the same photoshoot across training and testing. It might be better to have all the images from each toast-making photoshoot go into either one category or the other. For small hand-crafted datasets like mine it’s not too hard to group them by hand. In general I could see using metadata like timestamp and location to automatically group images into correlated subsets.
Data could also be flagged for similarity through an automatic process, with human review to see whether it’s a true duplicate or meaningfully independent. For example, two independent images that contain the same book might be flagged as containing the same thing based on the identical cover, while two identical toasts must be the same toast (or perhaps different copies of a book with toast on the cover?). The algorithm does not know or care that in real world situations you might see duplicate books but every toast is unique, so it’s up to us to design tests that reflect reality.
Or in my case, I’m using the same plate and cutting board in multiple photoshoots. As long as I use it for both Avocado Toasts and Not Avocado Toasts, I can hope that my model won’t be memorizing what my plates look like and using plate features to guess what toast is on it, but the thin stripes on my plate seem very easy for this kind of AI to recognize. If 60% of the times this plate is used on avocado toast and 40% on not avocado toast, my model might take that into account.
Is it better to pay more attention and try to get all my numbers even, to standardize how I make my variations? Or maybe those little statistics really do add up to have true predictive power of the sort that AI is really good at calculating. For example, maybe I should standardize how I take my lighting variations. I ate a lot of avocado toast outside during the summer, so those are the only ones with direct sunlight, and maybe I don’t want my AI to be fooled into thinking the harder edges and high contrast of direct sunlight is a distinctive feature of avocado toast. But maybe it should! Maybe direct sunlight is correlated with the particular heirloom tomatoes that were in season, which taste very good with avocado, and that little statistical correlation combined with some unconscious human predisposition to putting avocado toast on red plates plus many other correlations all add up to a strong prediction despite none of it having anything to do with recognizing the shape and color of avocado. Maybe this will remain true in general, even when testing on images I didn’t create.
It might be best to not test on images that were created specifically for ML model creation at all. If I test on a whole photoshoot image set, those results will be correlated with each other. If I pick a random representative from the set, maybe I’ll get the fully formed toast at its most divergent, but maybe I’ll get the plain slice from earlier in the shoot. Since all my photoshoots start with plain toast I have a lot more data on that sort of toast and I’d expect the model to perform better than it would with any random toast. Maybe I should pick the last image, or a random image from the last 5 images. But I do want to test on plain toast sometimes, too! But would hand-picking my test set based on my intuition lead to more accurate results, or simply introduce bias?
Most AI research uses one of a few standard datasets with standard train/test splits so that the performance of the algorithms can be compared fairly. This is helpful when reading research, though it’s possible to get stuck on the details of what performs better on those particular datasets, and when you’re comparing performances over 98% I worry the whole field is overfitting their techniques to a few particular datasets and the style of those datasets. These standard datasets are artificially ideal for the exact algorithms people are trying to make incremental improvements on. They have the same amount of data in each category, it’s all cleaned and uncorrelated and evenly spaced, and photos follow human aesthetic norms for photos they would share in a social context.8 I think the biggest room for improvement is on the human side of data creation and collection, but we’ll need to change our methods in order to see those improvements.
For the right type of AI and with the right data structuring, more data should in theory always be better. But there’s a myriad of ways that more data can mess with your results if you’re not careful, and sometimes these pitfalls are only discovered through luck after they have already happened.
While I was working on this post Jabrils published a video9 that demonstrates how a dataset with multiple similar images of pokemon can decrease the quality of results when creating images using an autoencoder. My intuition is that this makes sense because the multiple similar images weight the autoencoder to value features that are almost identical between different headshots of the same pokemon, with less emphasis on the features shared between different unique pokemon. He got better results by deleting most of his dataset, which was counterintuitive to many commenters on the video, but made perfect sense to me having been working on this problem for a while.
Appendix 4: Addressing Ethical Concerns about Plain White Toast Bias
Perhaps I should be more concerned that having plain toast over-represented in my dataset will make my AI model focus on plain toast to the detriment of other toasts.

With so many examples of plain toast in both the training and test sets, my AI might be incentivized to specialize in plain white toast accuracy and still get a decent score, because plain toast shares plain toast features. Learning those features would be easier than trying to learn how to recognize all the different features of toast-with-stuff-on-it. Our AI might decide toast-with-stuff-on-it is too diverse to bother accommodating:

Plain white toast might be more common in the real world than other kinds of toast, so it’s not necessarily a bad thing if our AI is biased toward it. The reason we have more plain white toast data in the first place is because I’m taking real photos of the toast in front of me, and there’s simply more plain toast, so our dataset reflects reality. And if the texture of plain white bread is easier to recognize, well, I don’t have a problem if our AI has the potential to perform extra well on plain toast for purely mathematical reasons. So it’s probably fine.
For another example, you may have seen the iconic Google Deep Dream images where everything is dogs. Why is everything dogs, when this AI is trained on so many other things? And in fact, the dataset it uses10 follows the good-practice standard of having every category of thing have the same amount of photos. I’m not quoting exact numbers, but it’s something like:
- 1,000 photos of birds
- 1,000 photos of cats
- 1,000 photos of trees
- 1,000 photos of dachshunds
- 1,000 photos of golden retrievers
- 1,000 photos of houses
- 1,000 photos of border collies
- 1,000 photos of pugs
- …and so on
This is a tricky thing. Socially and linguistically, we do differentiate between different kinds of dogs. It would make sense for our AI to look at a dachshund and label it “dachshund”, look at a cat and label it “cat”, look at a bird and label it “bird”. One’s a breed, one’s a species, and one’s a whole entire taxonomical class, but we end up with an AI that is 1% bird and 10% dog. The AI is trained to think dog-like features are ten times as important as anything else ever.11
When I made my Avocado Toast AI, I made a choice to train on two categories: Avocado Toast and Not Avocado Toast. I wanted an AI that was 50% avocado toast, not one that was 10% avocado toast, 10% plain toast, 10% peanut butter toast, etc. My goal with this project is not to represent reality, my goal is to feed avocado toast to an AI and learn from the experience.
As far as I know, standard practice to solve these kinds of problems for actual image recognition applications is to do sub-categories separately: have an AI trained on 1% dogs and 1% cats, and if you get dog then run it through another algorithm that specializes in dogs. And perhaps this is the third step, after first categorizing it as an animal rather than a plant or object. This doesn’t work for all kinds of AI and applications, and it requires having a strict taxonomy where all things at each level are treated as equal, which doesn’t reflect reality. You have to choose which dogs will represent all of canine kind in your reduced dataset, and whether avocado toast is a top-level category or a subcategory of Not Plain Toast.
Point is, the world is full of such algorithms making real decisions that impact people’s lives, trained on the equivalent of too many dogs or too much plain white toast.
If I’m creating my own ML model for custom data rather than a standard set then I have to make choices about what makes sense given the type of data I’m using and how it is created, and also how it is meant to be used. Going with an existing AI model is a choice too, and it is by no means an impartial one. All we can do is do our best, and keep an eye on the results rather than trusting the algorithm. Sometimes it involves better fitting the algorithm to the dataset, and sometimes it’s about changing the dataset to fit the algorithm, and in the best case you can fit both to each other.
I sometimes hear concerns that meddling with the model or data creates room for human bias to sneak in, similar to concerns about p-hacking or data dredging.12 This is a good thing to watch out for, but it’s often used as an excuse not to try. It doesn’t matter if you stop more bias from sneaking in, the bias is already inside the house. Machine learning is useful exactly because real data is lumpy, clustery, and correlated, rather than a perfect even grid of points in N dimensions. The world did not come pre-defined with everything sorted into standard categories of standardized size. We’re making and breaking categories all the time, and sometimes the way we label things (or people) has far-reaching effects.
Fortunately for me, there are specialists who can help with best practices, audit algorithms, and consult on datasets and collection. If you’re involved with an AI that actually affects people’s lives, make sure you’ve got someone on the job who has expertise in these matters.13 Some folks see AI ethicists as there to be some bar to pass just before (or even after) product release, for legal or PR reasons, but if you let them they can help you make sure that at a fundamental technical level your thing is doing the thing you want it to do rather than filling the universe with dogs. That’s better to find out sooner rather than later.
Even with the best experts and best intentions, it’s still essential to keep an eye on how a model performs in the real world and whether what it’s doing makes sense. No amount of data can simulate the real world, all models are flawed to some degree, and as with all things you just have to be open to recognizing your inevitable failures and doing your best to make things right.
We also need to stay aware of when trying to implement a particular AI might not be worth the societal cost. There may be cases where training a high-performing AI requires labeling and categorizing people beyond what people are ok with, and even if the resulting AI does good things, the ends might not justify the means.
As for me, I’ll stick to toast.
Appendix 5: Is Baby Yoda REALLY Avocado Toast?
I wasn’t lying when I said in section 4 that those were the real labels my AI applied to those photos. But I did have a narrative arc I wanted to create in this article, and I did what I had to do to get that story.
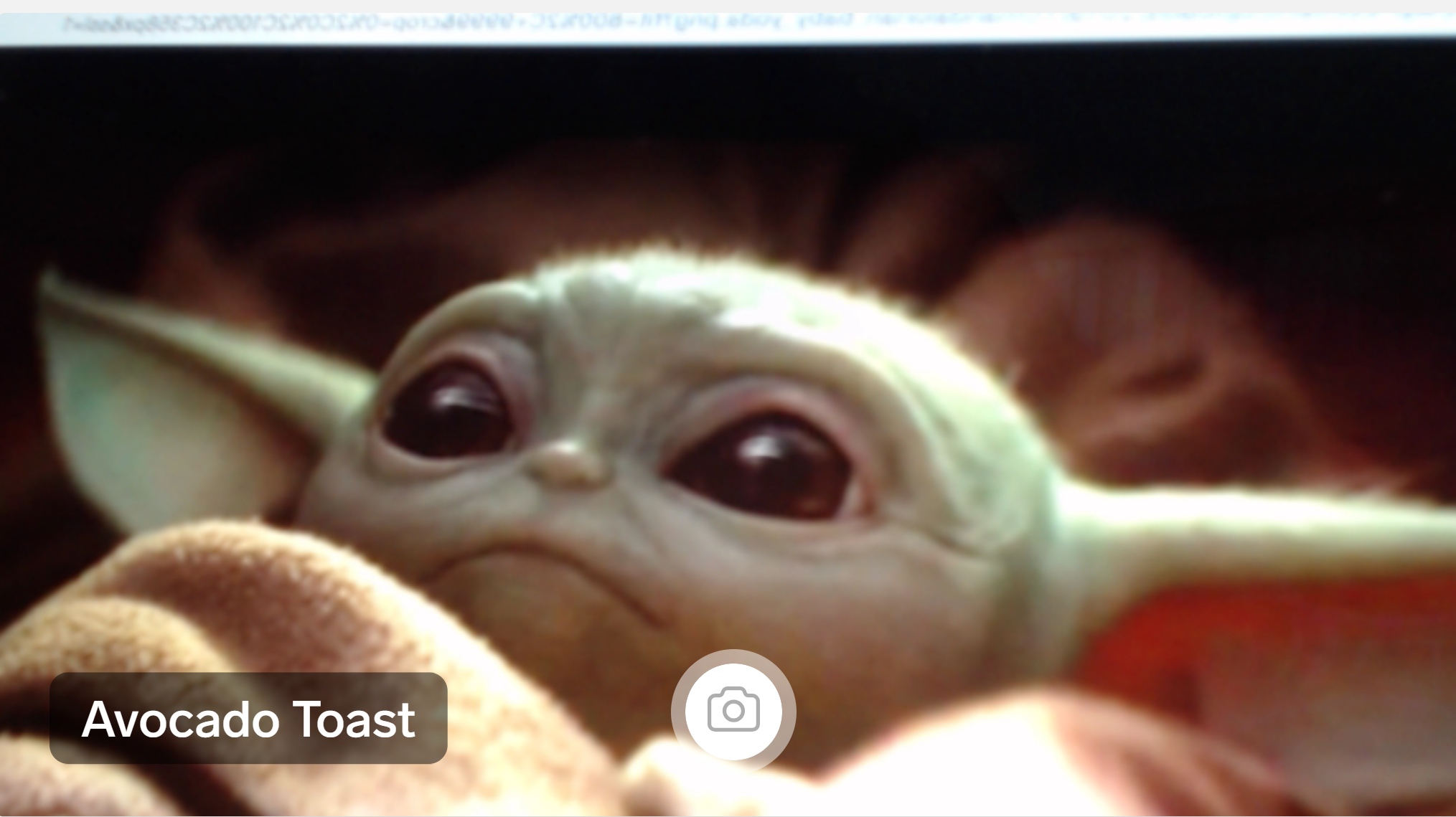
Obviously the AI has no experience with anything besides toast. I thought Baby Yoda was a good candidate to be judged as Avocado Toast because he’s green and has ears reminiscent of an avocado slice, though I figured that given the small size of my dataset and the lack of training on non-toast things, it would be basically random. The first image I tried was unfortunately judged to be Not Avocado Toast:

I printed it out and grabbed some colored flashlights so that I could tweak the image by hand in real time using the AI’s webcam interface. I thought maybe a greener tint would work. In fact, it was a strong red tint that changed the categorization:

I played around with a red and green flashlight to try and get Baby Yoda to appear with his natural skintone while also adding enough red to keep him categorized as Avocado Toast.


I tried a bunch of other pictures, angles, crops, etc, and found that most of them wanted to be Not Avocado Toast at first, but could be nudged into Avocado Toast:

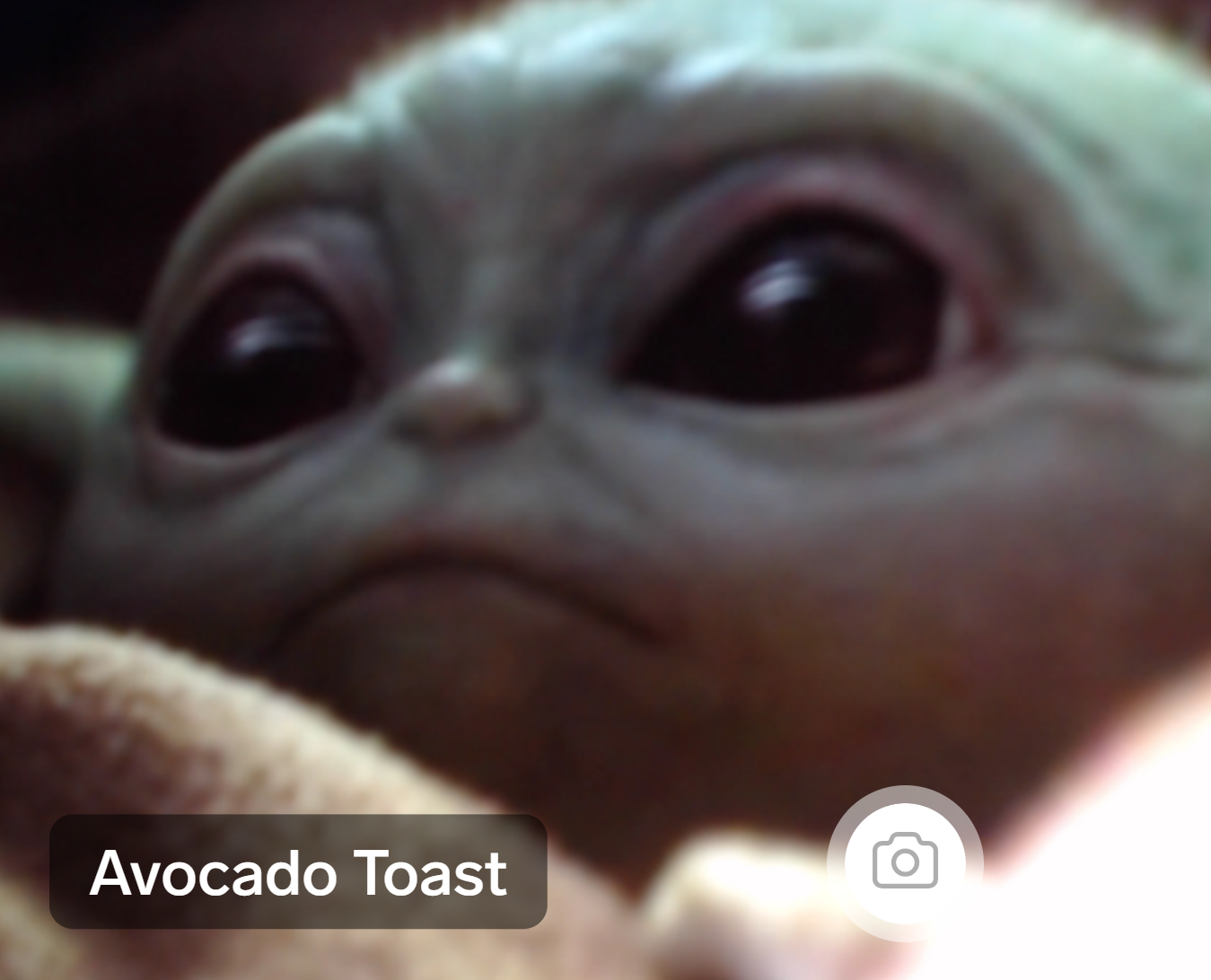



Buckbeak and Samwise were even more difficult. After several failures I cherrypicked some photos with green backgrounds in the hopes that they would be easier to nudge into the categorization I wanted, which finally worked.
So yes, perhaps I cheated a bit to get these characters to be Avocado Toast. But it wasn’t quite as cheatery as I intended, because for many other characters I could not get them to register as avocado toast no matter what I did.14 Severus Snape is stubbornly not avocado toast, no matter what photo and variation I tried. He just isn’t avocado toast, and that makes Snape and Baby Yoda fundamentally different.
So the truth is, Baby Yoda really is more Avocado Toast than most. I could get any photo I tried of Baby Yoda to categorize as Avocado Toast with some variation or another, which wasn’t the case for any of the other dozen characters I looked at. Though if this weren’t the case I still would have written the main part of this article the way I did with no regrets; only this appendix would’ve been a little different. Something to keep in mind when you’re out there reading pop tech articles about AI!
Conclusion and One Last Plea for References, plus a weird rant about dolls
I’m sure folks are working on things related to all the above topics, please send me references! And if you’re one of these folks, would love to hear your take. I hope this articulation of the problem helps spark some new ideas on the topic, and that you’ll look at toast with new appreciation.
I want a world where individuals and small groups can create their own AI using their own data, and so it’s vital to get the best performance possible out of smaller sets of correlated data. In order to leverage AI technology to increase human potential we shouldn’t have to rely on a few giant corporations, widespread privacy violation, and wastefully huge computations that require awesome amounts of computational power as well as energy use.
I want a world where we respect individuals’ rights, including their rights of privacy and property. Currently, tech companies feel that in order to be competitive they must push the boundaries of privacy and undervalue individual contributions, otherwise it is impossible to get enough data to make their technology economically viable. Perhaps with better techniques we can respect people’s data privacy as well as unleash the economic potential of data labor.15
Most of all I want a world where we use technology as a tool to boost our humanity, not one where technology eats away at us as we struggle to meet what it demands of us, while simultaneously making excuses for the harm it causes. As much as I anthropomorphize my avocado toast AI in this post, it’s no more than a bit of simple math.16 Any needs or desires it has are just a reflection of my own.
Playing with AI is like playing with dolls, it’s a chunk of myself I’ve externalized and personified as “other” in order to experiment with my perspective and my desires. I accept my Avocado AI as my own self-expression in algorithmic form, and I take full responsibility for its lust for cholesterol. I have no intention of cutting off that piece of myself and pretending it’s outside my control.
I wish the rest of the industry would catch up, because it’s kind of creepy, like, imagine you go to the bank and a full-grown adult is playing with a barbie doll and she says to you in a squeaky voice “You can’t have a loan! You’re not good enough!” and then she says to you in her normal voice “Oh, I’m so sorry, I wish I could help you buy that house, but Bank Manager Barbie has the final word on this matter. She’s an expert.” And then there’s a giant press event where she does this in front of the entire tech industry with no self-awareness whatsoever, and everyone eats it up. 17
Anyway, my avocado toast AI is good and I like it, the end.
- See appendix 4
- For example, see this paper on using experts to manually augment a melanoma dataset: https://arxiv.org/pdf/1702.07025.pdf
- Here’s a few papers related to data augmentation that I read while researching this project: https://arxiv.org/pdf/1712.04621.pdf , https://arxiv.org/pdf/1609.08764.pdf , https://arxiv.org/ftp/arxiv/papers/1312/1312.5402.pdf
- We didn’t train this particular AI to ask “how chaotic and/or evil is this avocado toast?”, though that would be a perfectly reasonable next project.
- see the Soylent phenomenon
- This paper has some actual data and graphs on the subject: https://arxiv.org/pdf/1707.02968.pdf
- Used Black Lotus cards start in the tens of thousands of dollars and can sell for over 100k depending on the particulars. Their use has now been banned in most tournament formats.
- In the final stages of editing this post, a relevant paper and dataset were published called ObjectNet,( https://objectnet.dev/objectnet-a-large-scale-bias-controlled-dataset-for-pushing-the-limits-of-object-recognition-models.pdf ) a test image set designed to look more like real world situations and less like perfect share-able photos, with objects appearing at a variety of ugly angles and with cluttered varied backgrounds. Not surprisingly, they showed that prize-winning AIs with accuracy in the high 90s (according to those AI’s own self-administered tests) struggled to get 50% accuracy as soon as they were confronted with images that didn’t follow the same stylistic norms as the ones they were trained on.
- “AI Draws New Pokemon Using Simple Math”, Jabrils, Nov 9 2019, https://www.youtube.com/watch?v=pWix8hMIfWA
- which is a subset of ImageNet, http://www.image-net.org/
- Features shared between dogs and other animals, such as eyes, are even more emphasized.
- Similar to what I did with Baby Yoda, keep messing with it until I get the completely un-biased impartial AI-created results I was looking for. See Appendix 5.
- This person is not me, but I trust you can do a search.
- Though I am confident that an adversarial attack from another AI would have had no trouble making any character register as Avocado Toast with tiny tweaks not visible to the human eye, such as by putting in that pattern of 6 brown conspiracy pixels as referenced in section 3. But I’m working with only lighting and camera angles.
- We talk about Data as Labor / Data Dignity / whatever-it’s-called quite a lot around here, see https://theartofresearch.org/projects/data-dignity/ for references.
- Well, maybe a lot of simple math, happening very very fast.
- Bank Manager Barbie gets the cover of Forbes. Bank Manager Barbie is the highest paid bank manager ever, and her salary goes to the manufacturers of the plastic, while the humans who wave her around, make decisions, and express them in a squeaky voice make less than minimum wage because their work is considered unskilled. Bank Manager Barbie becomes a tyrant, ruling the lives of the humans beneath her. Those who become the Voices of Bank Manager Barbie are seen as mere mouthpieces executing our overlord’s will, and everyone just kinda goes with it.